A General Framework for Building AI Agents

Last summer, I built an AI agent that used LLM-as-a-judge. While promising in theory, its accuracy was too unreliable for production—each LLM step often worsened the output rather than improving it. When it worked, it felt like magic, but too often, it missed obvious errors or produced inconsistent assessments, making it untrustworthy.
We ultimately kept humans in the loop for quality control. This raised a fundamental question: if AGI is supposedly imminent, why can’t LLMs reliably evaluate their own output? The answer lies in probability.
An LLM that is 70% accurate in generating responses will also be 70% accurate in verification. The probability of both steps succeeding is only 49% (0.7 * 0.7)—essentially a coin flip, which is useless for building robust systems. To develop reliable AI agents, we need a structured framework that mitigates stochasticity while controlling LLM costs and human labor. Caveat: this is an extremely crude model for how things work and the reality is full of nuance, but I hope it gets the point across.
First, Forget About Tooling
There are dozens of agent vendors on the market, but none will ultimately replace the creative, domain-specific work needed to make AI systems useful today. Tool vendors have a clear incentive to position themselves as solving your problems, but the work that will grant you a competitive advantage lives outside what’s on offer to everybody else.
Instead of getting caught up in the latest tools, it’s essential to focus on first principles thinking—breaking down problems to their fundamental components and designing solutions from the ground up. In other words, everything an agent tool can offer should be fairly achievable with the primitives offered by the fronter model companies, if you do anything yourself with losing much time.
WTF is an AI Agent?
Since there’s no universally accepted definition, I’ll offer one here: an AI agent is a software program that autonomously performs repetitive or decision-based tasks. A practical example? Imagine an agent that disputes a bogus health insurance bill on your behalf and successfully gets the claim covered.
As I discuss in “Eval-Driven Development,” AI workflows are deceptively easy to prototype but extremely difficult to get working reliably. This is the core problem everyone in the AI industry is trying to solve—and the reason the role of “AI engineer” has emerged.
Building Reliable Agents
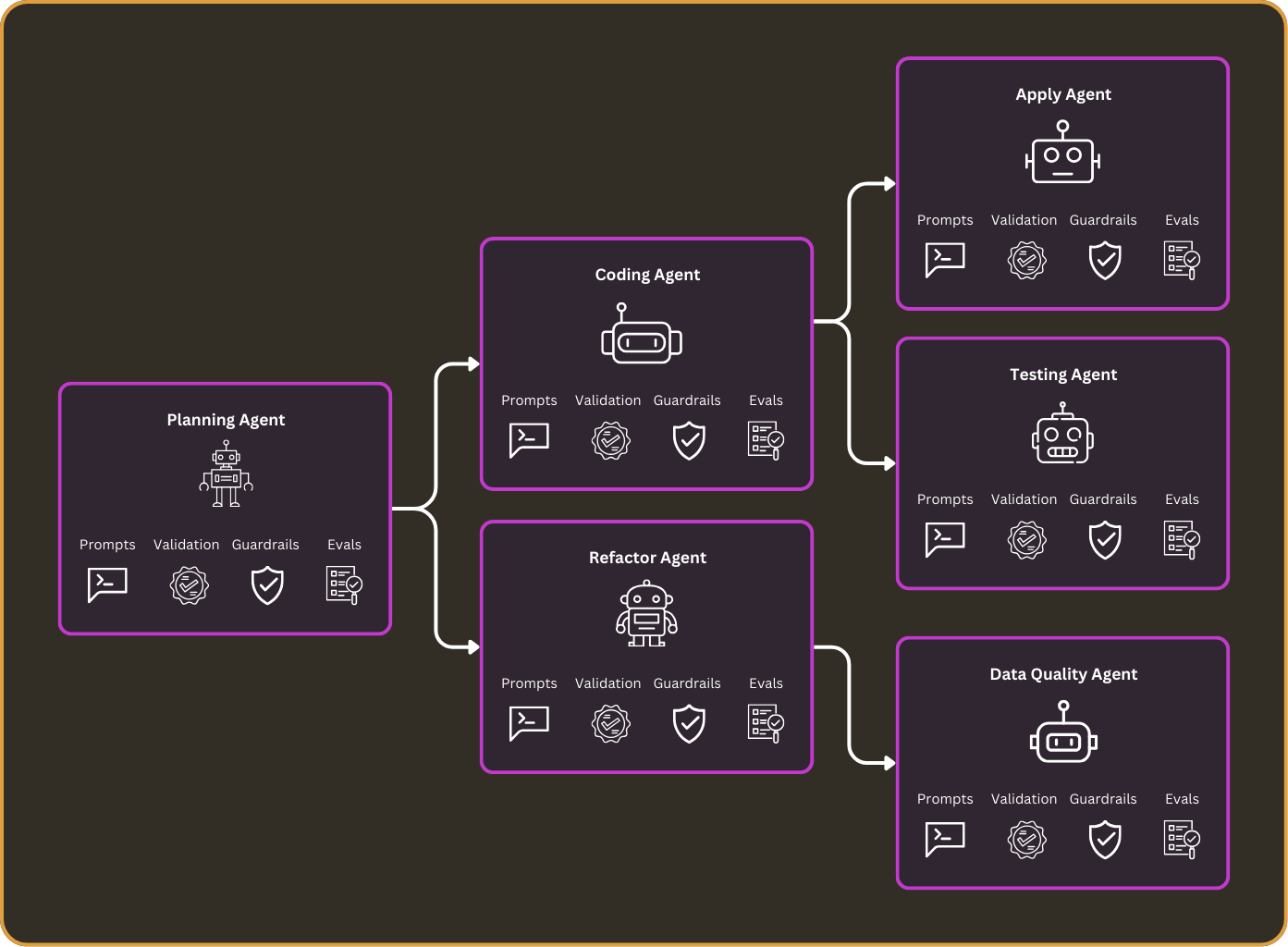
Through my experience, I’ve identified five core strategies AI engineers can use to develop more reliable AI agents:
1. Prompt Tuning
This involves experimenting with different prompt engineering techniques—varying context, modifying instructions, and tailoring inputs to specific models. Retrieval-augmented generation (RAG) can also be used to incorporate relevant context dynamically before prompting.
2. Validation and Guardrails
This step ensures that an LLM’s response is appropriate before it’s returned to a user. If an output doesn’t meet predefined criteria, the system should retry or apply corrections. Guardrails can filter out hallucinations, enforce formatting rules, and improve safety.
3. Evaluations (Evals)
Evaluations are the most critical yet difficult part of building AI agents. Determining whether an AI output is “correct” is an open-ended problem that often requires a combination of human review, automated verification, and LLM self-checking. There’s ongoing research into improving LLM evaluations, but it remains an unsolved challenge in the field and will like be for years to come.
4. Use Domain Expertise
Learning an LLM’s behavior for your domain and tailoring solutions are a deviation from typical software engineering or machine learning research principles—where we strive for generality—yet one that seems necessary with AI. Adding domain-specific business logic or prompt rules can help you eek out more reliability from your LLMs.
5. Fine-Tuning
Everybody knows about fine-tuning, but it’s costly to get right and requires complex workflows to make continuous improvements. The first four points can typically be done more cheaply and quickly to tune performance.
Conclusion
Building AI agents that can operate reliably in production isn’t just about better tooling or more compute power—it requires slightly more than a surface level understanding of what an LLM is doing, a willing to experiment and fail, and a deep understanding of how LLMs behave in your domain. By focusing on structured development approaches and mitigating the inherent randomness of LLMs, we can move toward AI systems that are not just promising in theory but genuinely useful in practice.