Eval-Driven Development (EDD)
You’ve probably heard of Test-Driven Development (TDD). Now, I want to propose a new paradigm for developing large language model (LLM)-based applications: Eval-Driven Development (EDD).
What is Eval-Driven Development?
LLM applications tend to follow a fairly predictable lifecycle. It usually starts with excitement—you type in a problem statement, craft a prompt, and suddenly, the model generates results that feel like magic. This early success creates the illusion that LLMs can solve complex problems effortlessly. Your pupils transform into dollar signs. Optimism takes hold, and it’s tempting to believe you’ve built a game-changing product.
Then reality hits.
Once you integrate live data and deploy your system into production, you realize your model is only correct about 60-70% of the time — if you’re lucky. Your mileage may vary — no, WILL vary, wildly. Customers start encountering edge cases where the model fails, their frustration will mount and they’ll run screaming to one of your two-dozen competitors. Now, you’re stuck with a project where success hinges on closing the gap between an acceptable reliability threshold and the system’s current performance.
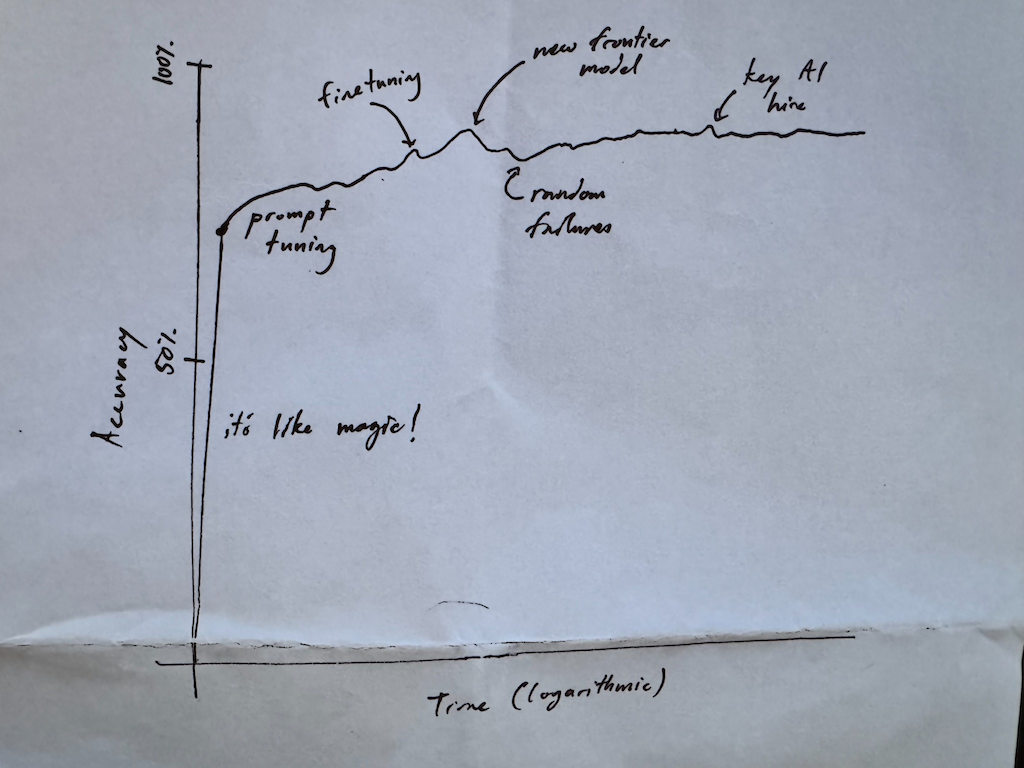
Closing The Reliability Gap
In traditional software development—Software 1.0—correctness was largely deterministic. We built systems with an expectation of near-perfect reliability. With LLMs, however, anecdotally, we often start much lower. This is an entirely different quality bar, and customers accustomed to deterministic software may not tolerate such inconsistency.
If your application involves generating creative content that undergoes human review, you have more flexibility. But if you’re building an LLM-powered system that needs to operate autonomously or replace traditional software, your competitive advantage comes down to one thing: closing the reliability gap. The best LLM products today succeed not because they use the most powerful models, but because they optimize relentlessly to move from 70% reliability to 99%.
Don’t Succumb to Vibes-Based Development
What I’m going to propose is hard. Like TDD, it requires disciplined effort up front before seeing the fruits of your labor — but like TDD, it will result in a better, more competitive product.
Instead of relying on the vibes of your LLM output, start by:
- building a benchmark dataset that you can run across multiple models. Tediously review and catalogue the failure modes.
- Understand the variants of your problem spaces that are likely to be the most problematic.
- Build a mental model of the guardrails and validation that you’ll need to do to ensure your customers are getting what they need.
- Most importantly, develop a point of view of how to measure a successful LLM output, i.e., your eval.
Now you have a starting point, and you can build upon this initial data as you roll things out to production.
By starting with a high-quality baseline, you shift your development mindset. Rather than treating your LLM system as a black box, you approach it as an optimization problem. Your real work begins once you understand the gap you need to close.
The Long Road to Optimization
Achieving near-perfect reliability in a domain will be a long road for every startup. The techniques for closing the reliability gap make up the brunt of creative problem-solving for LLM applications. These techniques are unlikely to be widely shared [1]. No one truly knows which combination of retrieval-augmented generation (RAG), fine-tuning, prompt engineering, and system-level optimizations will yield the best results for a given application. That’s the secret sauce of market-leading LLM products and where the competitive advantage currently lies.
What we do know is that blindly deploying LLMs and depending on vibes without a solid evaluation framework is a costly mistake. Eval-Driven Development ensures that you’re making data-driven decisions at every stage, ensuring a steady march toward success.
Final Thoughts
If you’re building LLM-powered applications, start with evals. Measure your baseline. Understand the problem space deeply. Only then can you systematically work toward the reliability required to make your product viable.
In this new era of AI, the companies that master evaluation and optimization—not just prompt crafting—will be the ones that lead the market. Eval-Driven Development isn’t just a best practice; it’s the only way to build robust, reliable, and scalable AI systems.
[1] Though sometimes they are shared! Open source projects are a gold mine for learning how engineers are achieving success with LLM apps. Bolt and Aider are two excellent examples to study.